
Towards Efficient Interaction for Personal Health Data Queries on Smartwatches
Bradley Rey , Charlies-Olivier Dufresne-Camaro, Pourang Irani
Published in MHCI, 2023
Abstract
The smartwatch is rapidly becoming a go-to personal health tracking device, allowing for the collection of a broad range of personal health data. Yet, access to this data is often limited to discrete glanceable visualizations. This in part is due to a lack in our understanding of the queries desired to access such data. Thus, as practitioners and application designers, our ability to enable efficient exploratory interactions is limited. In this work, through analysis of a public dataset, we characterize personal health data queries desired for exploration on the smartwatch across multiple dimensions: (i) data requested and attributes of this data, (ii) aggregation methods, (iii) mechanisms for filtering, and (iv) interrogatives used. We conclude with discussion around our findings that can be utilized in future works aimed toward enabling efficient interaction with personal health data on the smartwatch.
In Summary
Smartwatches are popular for personal health tracking, but access to the collected data is often limited to simple, quick visualizations. To begin to support further exploration, we analyzed a public dataset to identify aspects of health data queries people are interested in, including the data requested, how it is aggregated, filtering methods, and the types of questions asked.
Key Findings
Four components can be seen to make up a personal health data query. These include the interrogative or question word(s), the data subject or attribute(s), the aggregation term, and the filtering mechanism. Importantly, however, not all are needed when querying data. At a minimum, all queries in the dataset contain an interrogative and data subject. Thus, some queries do not contain aggregation or filtering terms, often implying exploration of a current value or of all data captured (e.g., “What is my resting heart rate?”). This is important for interaction of data on the smartwatch, as no matter the interaction modality considered, we must obtain this information at a minimum.
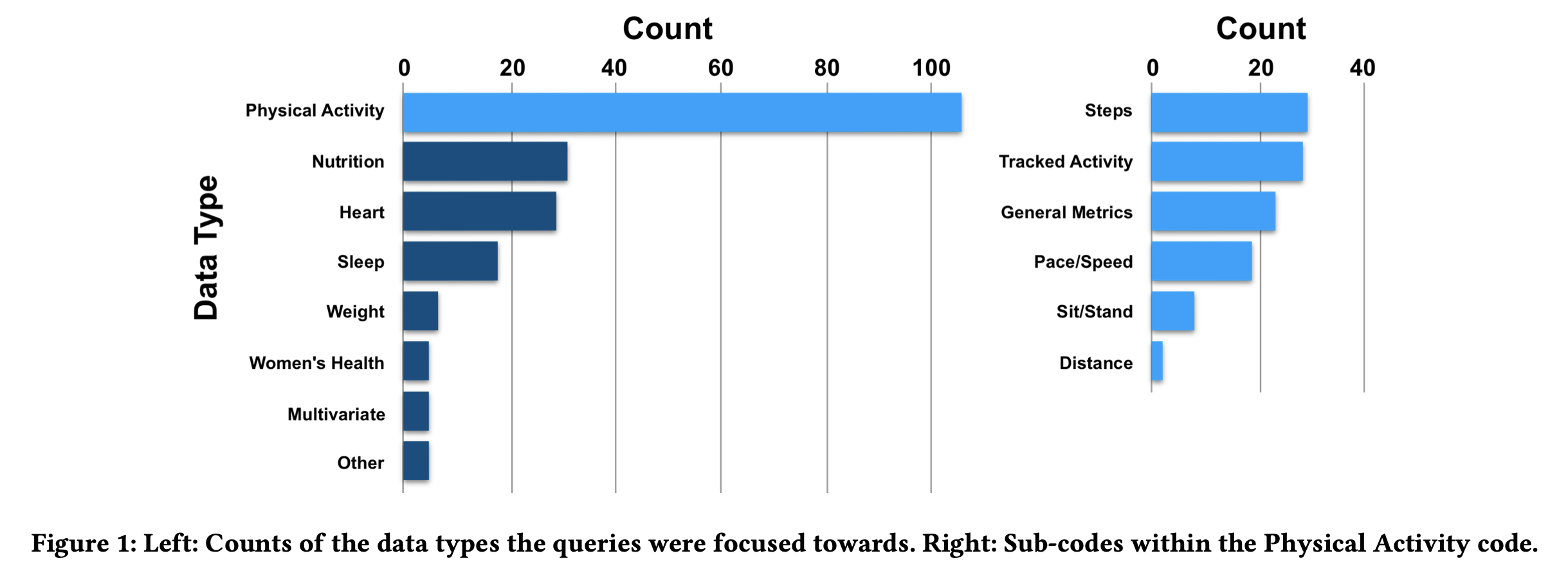
Data Attributes
Attribute references can be seen as words within a query that correspond to a data attribute or specific data point within the collected available data. These references were either (1) Explicit (~80% of queries), where the reference in the query was specific to a data point being captured (e.g., “What is my current heart rate?” and “How many steps did I get during that 2 km walk?”) or (2) Implicit, where the reference to data within the query was too broad, could hold different meaning for different people, or required collection of multiple data points (e.g., “Compare my running stats from the same time last year” and “Is my work out better at my home gym or commercial gym?”).
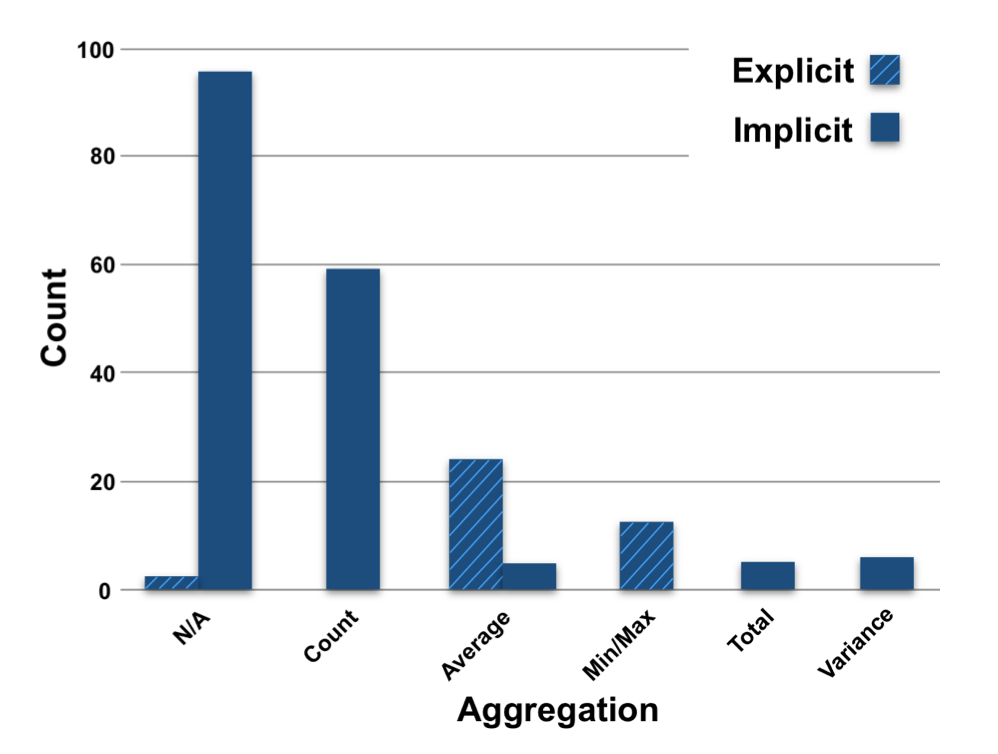
Aggregations
Our exploration of aggregations was first coded into the type of aggregation requested; see Figure 2. We found five forms of aggregation and a sixth non-aggregation form: (i) Count (e.g., “How many runs have I completed thus far in 2021?”), (ii) Average (e.g., “What is my average step count per day”), (iii) Min/Max (e.g., “What was my fastest kilometer in my run?”),(iv) Total (e.g., “How many miles have I accumulated through walking, running, and biking over the course of this year”?), (v) Variance (e.g., “How much has my pace fluctuated during my walk”), and (vi) N/A and Current value where no aggregation is necessary and a value is simply being requested (e.g., “What is my resting heart rate?”).
We further explored aggregation references through either ex- plicit aggregation, where direct reference to an aggregation transform was used, (e.g., “What’s my average walking pace per kilometer” → Average) and implicit aggregation, when phrasing was used, (e.g, “How long does it take after a walk to get back to resting heart rate?” → Average and “How many calories did I burn in the last 4 hours?” → Count). Notably, when we explore the aggregations through this lens, the vast majority of aggregations are performed utilizing implicit requests.
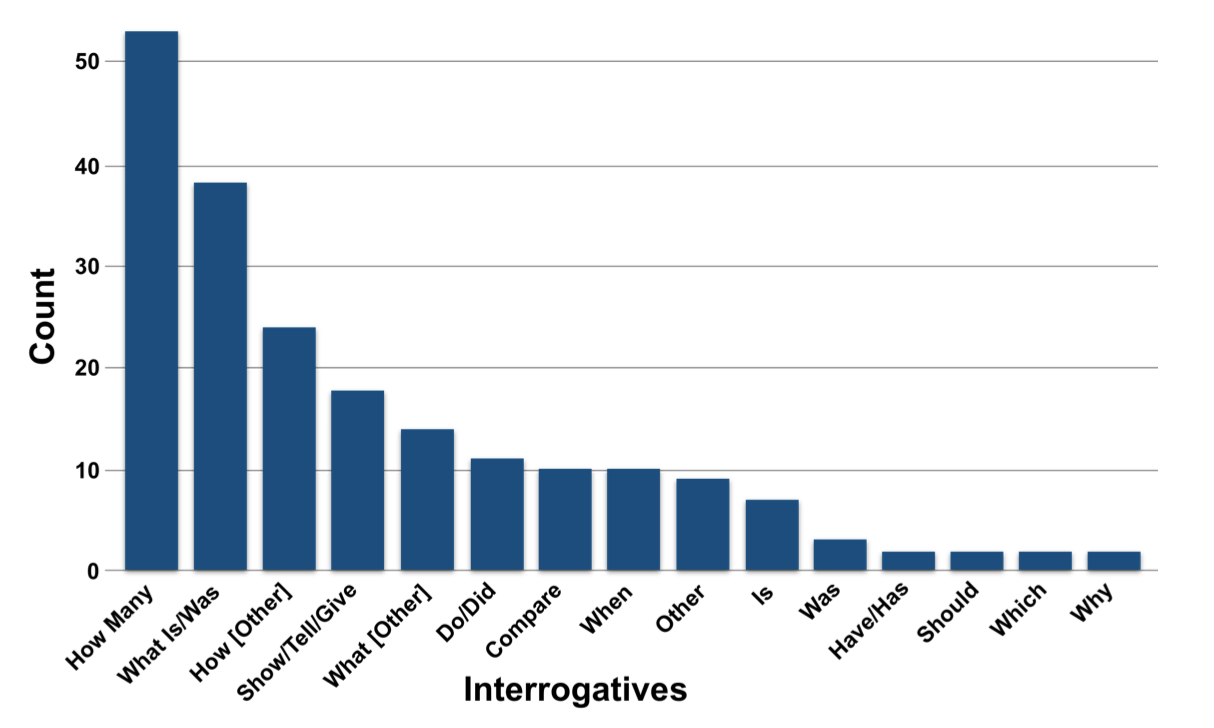
Interrogatives
Interrogatives, or question words, can provide insight into the aggregation desired. They can also indicate questions versus commands, and hint at appropriate forms of output (e.g., show me compared to tell me).
Filtering Mechanisms
Four codes were used to differentiate filtering mechanisms used within the queries: (i) N/A, where no filtering was needed as the entire data related to the query would be used, (ii) Current where the current or most recent value would be filtered removing data collected in the past, (iii) Time dependent, where a notion of time was used to filter data (e.g., “What was my highest heart rate in the last hour?”), and (iv) Activity dependent, where an instance of an activity is used to filter data rather than an explicit notion of time (e.g., “What was my best kilometer during my run?”, “Show me my heart rate chart from today’s gym session.”, or “Was the 1st km of my hike faster than the last kilometre today?”).
Notably, activity dependent filtering is a subset of time dependent filtering, however is referenced with respect to an activity or activities rather than the specific time frame for an activity.
In More Detail
Please review our paper and poster (linked above) for an abstract, analysis details, and complete results.